Part I: Foundations of Recommender Systems
From Collaborative Filtering to Modern Embeddings
Why Do We Need Recommendations?
The Problem
Too many choices, too little time
Without recommendations:
- Endless browsing, no discovery
- Miss relevant content
- Poor user experience
With recommendations:
- Personalized discovery
- Relevant suggestions
- Better engagement
Explicit Feedback
Users rate items explicitly (e.g., 1-5 stars)
| Titanic | Alien | Shrek | Avatar | |
|---|---|---|---|---|
| Alice | ⭐⭐⭐⭐⭐ | ? | ⭐⭐⭐⭐ | ? |
| Bob | ? | ⭐⭐⭐⭐ | ? | ⭐⭐ |
| Carol | ⭐⭐⭐⭐ | ? | ⭐⭐ | ? |
Goal: Predict missing ratings (?)
Challenge: Matrix is extremely sparse! (>99% missing in practice)
Implicit Feedback
Explicit ratings are rare! Most interactions are implicit:
- Watch: User watched a video
- Click: User clicked on an item
- Purchase: User bought a product
- Like: User gave positive signal
Interaction Matrix (binary: 0/1)
| Titanic | Alien | Shrek | Avatar | |
|---|---|---|---|---|
| Alice | ✅ | ✅ | ||
| Bob | ✅ | |||
| Carol | ✅ |
From Ratings to Interactions
Rating Matrix R
- Explicit feedback
- Clear preferences
- User effort required
Interaction Matrix X
- Implicit feedback
- Noisy signal
- No user effort!
Modern systems: Primarily use implicit feedback
Why? More data, less user friction
Collaborative Filtering
Key Insight: Users with similar tastes in the past will have similar tastes in the future
User-based CF
- Find users similar to Alice
- Recommend what they liked
Item-based CF
- Find movies similar to what Alice liked
- Recommend those
Pioneered by GroupLens (Resnick et al., 1994)
Matrix Factorization
Idea: Decompose sparse rating matrix into latent factors
\[R \approx U \times V^T\]

Matrix factorization visualization. Source: Google ML Guide
Matrix Factorization: Visual Intuition
From Koren et al. (2009) (Koren et al., 2009)
Each movie and user represented in latent space
- Dimension 1: Male-oriented ↔︎ Female-oriented
- Dimension 2: Serious ↔︎ Escapist
Prediction: Dot product of user and item vectors
Side Information
Beyond just interactions: Use metadata to improve recommendations
User Metadata
- Age, location
- Device type
- Time of day
- Historical behavior
Item Metadata
- Genre, director
- Release date
- Tags, descriptions
- Visual features
Benefit: Helps with cold-start (new users/items)
Enables content-based filtering
Embeddings
Word2Vec: The Embedding Revolution
Key idea from NLP (Mikolov et al., 2013):
Words with similar contexts have similar meanings
Skip-gram architecture:
- Input: Current word
- Output: Predict surrounding words
- Learn word embeddings as a side effect
Word2Vec: Learned Representations
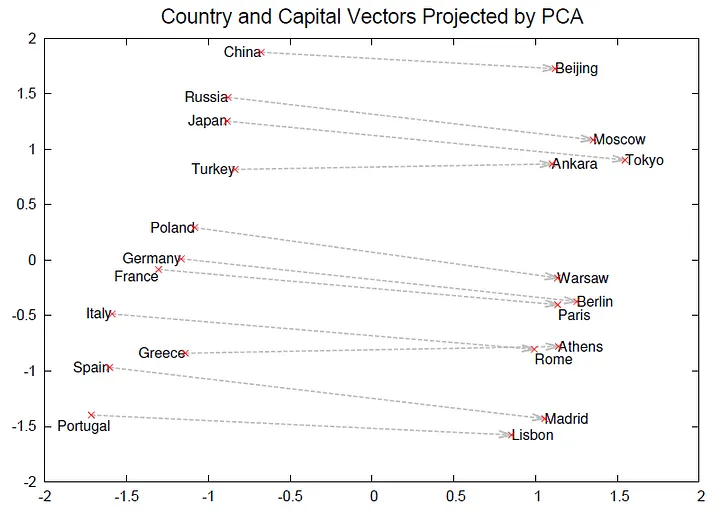
Word2Vec capitals example (Mikolov et al., 2013)
Vector arithmetic: King - Man + Woman ≈ Queen
Embeddings for Recommendations

Book recommendations example (Vančura et al., 2022)
Node2Vec: Embeddings for Graphs
Key idea: Random walks in graphs (Grover & Leskovec, 2016)
Almost any data can be represented as a graph
- Users & Items → Nodes
- Interactions → Edges
- Social connections, knowledge graphs, etc.
Learn embeddings that capture graph structure
Two-Tower Model
Dominant architecture for retrieval
Query Tower
- User features
- Context features
- → User embedding
Item Tower
- Item features
- Metadata
- → Item embedding
Scoring: Dot product of embeddings
\[\text{score}(u, i) = \text{user_emb}(u) \cdot \text{item_emb}(i)\]
Two-Tower: Why So Powerful?
Key advantage: Decouple user and item computation
- Precompute item embeddings offline for all items
- Compute user embedding at inference time
- Fast retrieval using approximate nearest neighbors (ANN)
YouTube (Covington et al., 2016):
- Candidate generation: Two-tower model
- Selects hundreds from millions of videos
- Millisecond-level latency at scale!
Retrieval → Ranking
Stage 1: Retrieval
Goal: Fast reduction from millions to hundreds
- Input: User context
- Output: 100-1000 candidates
- Methods:
- Two-tower models
- Approximate Nearest Neighbors (ANN)
Speed >> Accuracy
Stage 2: Ranking
Goal: Precise scoring of candidates
- Input: ~1000 candidates
- Output: Ranked list with scores
- Methods:
- Deep neural networks
- Gradient boosted trees
- Complex feature interactions
Accuracy >> Speed
Key Takeaways
- Collaborative Filtering: Users with similar behavior like similar items
- Matrix Factorization: Decompose ratings into latent factors
- Implicit Feedback: Use interactions (clicks, watches), not just ratings
- Embeddings: Core technique underlying all modern systems
- Two-Tower Models: Separate user and item encoding for scalability
- Two-Stage Pipeline: Retrieval → Ranking