Part II.a: Transformer Architecture Deep Dive
Understanding the Foundation of Modern NLP
Overview
- The Original Transformer
- Encoder-Decoder Architecture
- Encoder-Only vs. Decoder-Only Models
- The [CLS] Token and Text Embeddings
“Attention Is All You Need” revolutionized NLP and laid the foundation for modern LLMs
The Original Paper: “Attention Is All You Need”
Authors: Vaswani et al. (2017), Google Brain & Google Research
Key Innovation: Replace recurrent and convolutional layers with self-attention mechanisms
Original Task: Neural Machine Translation
Impact: - Enabled parallel processing (vs. sequential RNNs) - Captured long-range dependencies better - Foundation for GPT, BERT, T5, and modern LLMs
Detailed Encoder-Decoder View
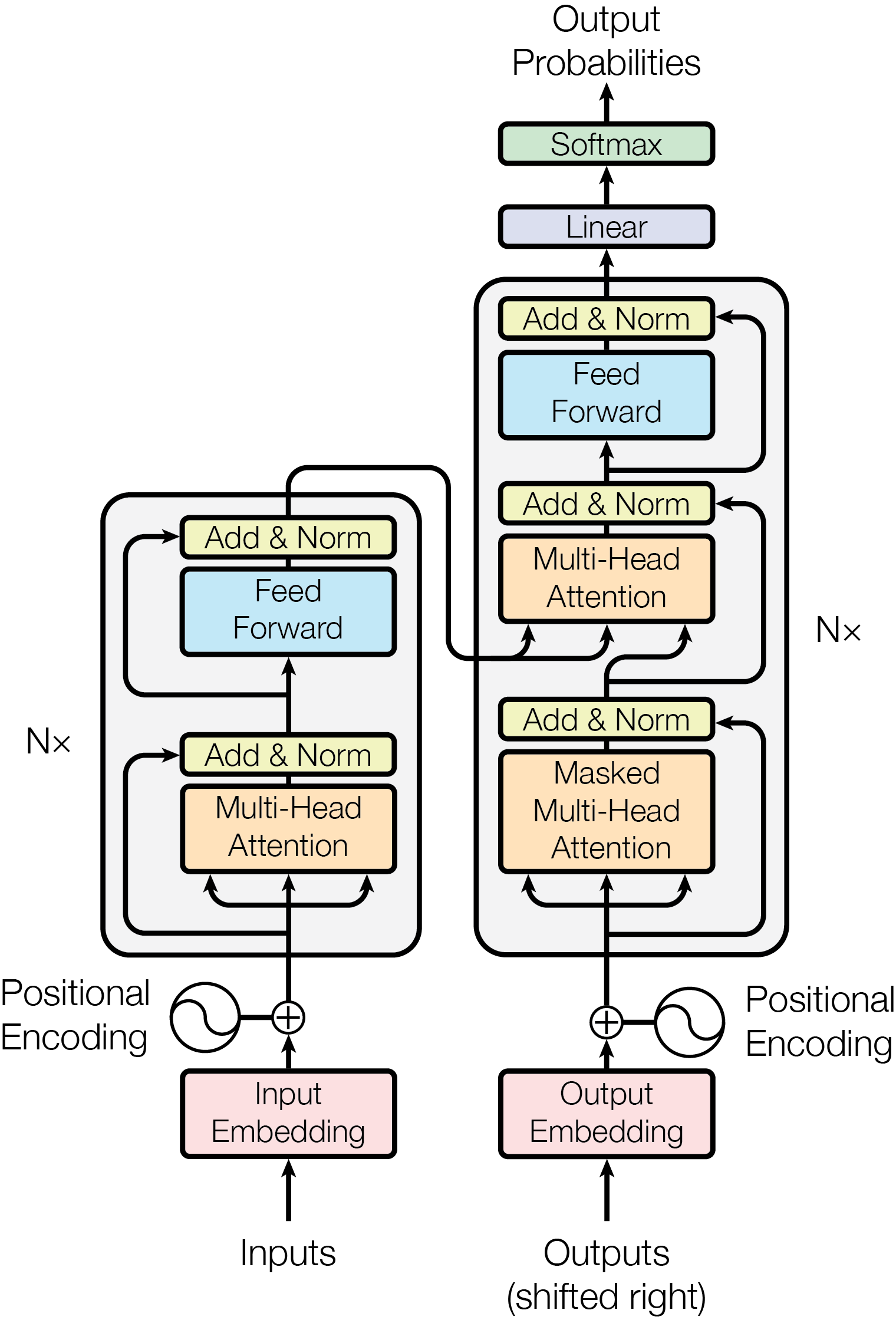
Encoder-Decoder architecture (Vaswani et al., 2017)
Multi-Head Attention
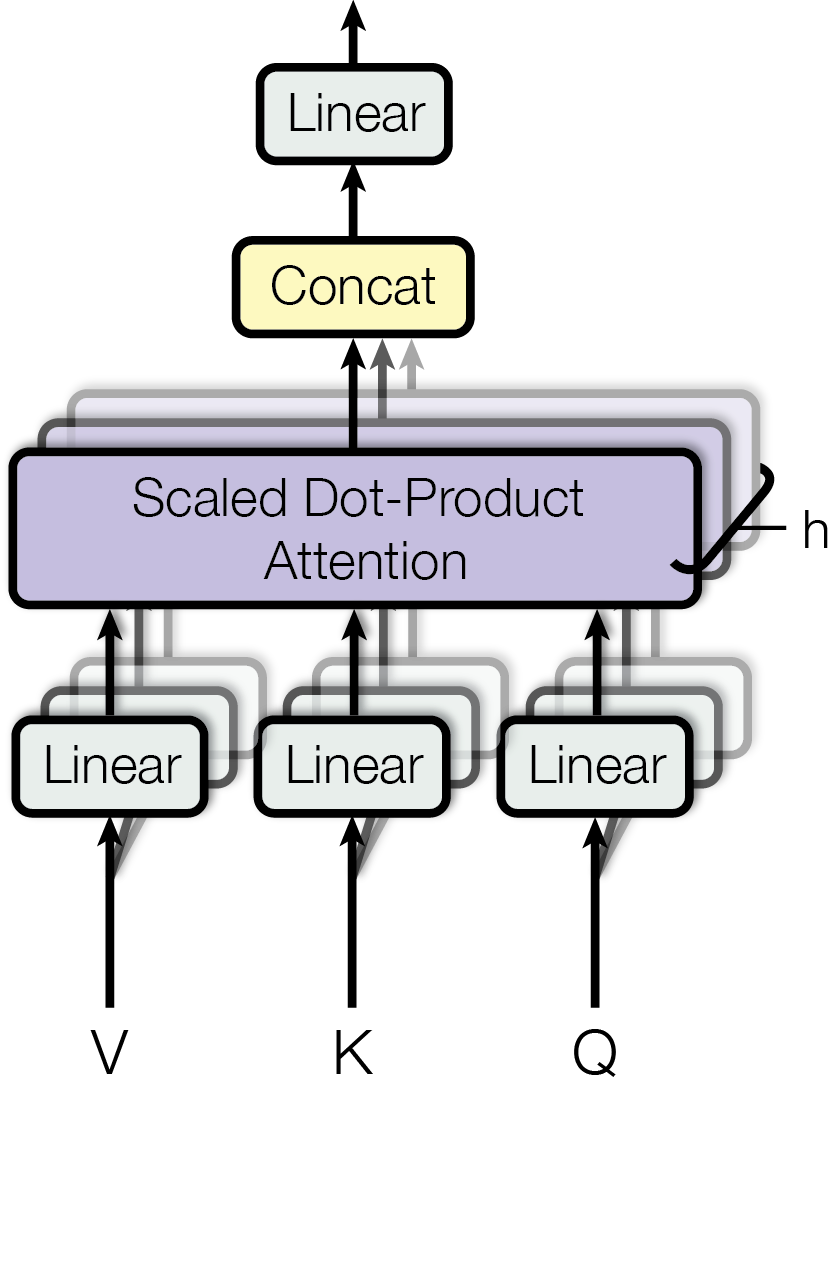
Multi-head attention mechanism (Vaswani et al., 2017)
Attention Mechanism Formula
\[ \text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right) V \]
Components:
- Q (Query): “What am I looking for?”
- K (Key): “What do I contain?”
- V (Value): “What information do I provide?”
- \(d_k\): Dimension of keys (for scaling)
QKV Intuition: Example
Think of attention like searching a library:
Query (Q): Your search request
- “I need information about climate change”
Key (K): Book titles/descriptions on shelves
- “Book about global warming” ← High match!
- “Book about machine learning” ← Low match
Value (V): The actual book content
Attention = Reading partially from all books, weighted by how well each Key matches your Query
Multi-Head Attention
Idea: Run attention in parallel with different learned projections
\[ \text{MultiHead}(Q, K, V) = \text{Concat}(\text{head}_1, ..., \text{head}_h)W^O \]
where each head is:
\[ \text{head}_i = \text{Attention}(QW_i^Q, KW_i^K, VW_i^V) \]
Positional Encoding
Problem: Self-attention has no notion of sequence order!
Solution: Add positional encodings to input embeddings
\[ \text{Input}_i = \text{TokenEmb}_i + \text{PosEmb}_i \]
Original approach: Goniometric functions (sin, cos)
Alternative: Trainable weights
Decoder
1. Masked Self-Attention (Causal)
- Cannot attend to future positions
- Only looks at past and current tokens
- Ensures autoregressive generation (one token at a time)
2. Cross-Attention to Encoder Output
- Attends to the encoder’s representations
- Connects source (input) and target (output) sequences
- Example: Translation - decoder attends to source sentence while generating translation
Detailed Encoder-Decoder View
Encoder-Decoder architecture (Vaswani et al., 2017)
Encoder-Only Models: BERT
BERT (Bidirectional Encoder Representations from Transformers) (Devlin et al., 2019)
Key Idea: Use only the encoder stack with bidirectional attention
Pre-training tasks:
- Masked Language Modeling (MLM): Predict masked tokens
- Next Sentence Prediction (NSP): Predict if sentences are consecutive
Variants: RoBERTa (Liu et al., 2019), ALBERT (Lan et al., 2020), DistilBERT (Sanh et al., 2019), CzERT (Sido et al., 2021)
Decoder-Only Models: GPT
GPT (Generative Pre-trained Transformer) (Radford et al., 2018)
Key Idea: Use only the decoder stack with causal (left-to-right) attention
Pre-training: Next token prediction
Evolution: GPT (Radford et al., 2018) → GPT-2 (Radford et al., 2019) → GPT-3 → GPT-4, LLaMA, etc.
Encoder vs. Decoder Models
| Encoder-Only (BERT) | Decoder-Only (GPT) | |
|---|---|---|
| Attention | Bidirectional | Causal (unidirectional) |
| Best for | Understanding tasks | Generation tasks |
| Examples | Classification | Text generation, completion |
| Training | MLM, NSP | Next token prediction |
| Context | Full sequence | Left context only |
The [CLS] Token
Introduced in BERT - Special token for sequence-level representation
How it works:
Input: [CLS] The movie was great [SEP]
↓ ↓ ↓ ↓ ↓ ↓
Encoder: Apply bidirectional self-attention
↓ ↓ ↓ ↓ ↓ ↓
Output: [h_CLS] [h_1] [h_2] [h_3] [h_4] [h_5]Key insight: [CLS] attends to all other tokens → learns holistic representation
- Aggregates information from entire sequence through self-attention
- Single vector representation (e.g., 768-dim for BERT-Base)
- Used for classification, embeddings, and downstream tasks
BERT Fine-Tuning
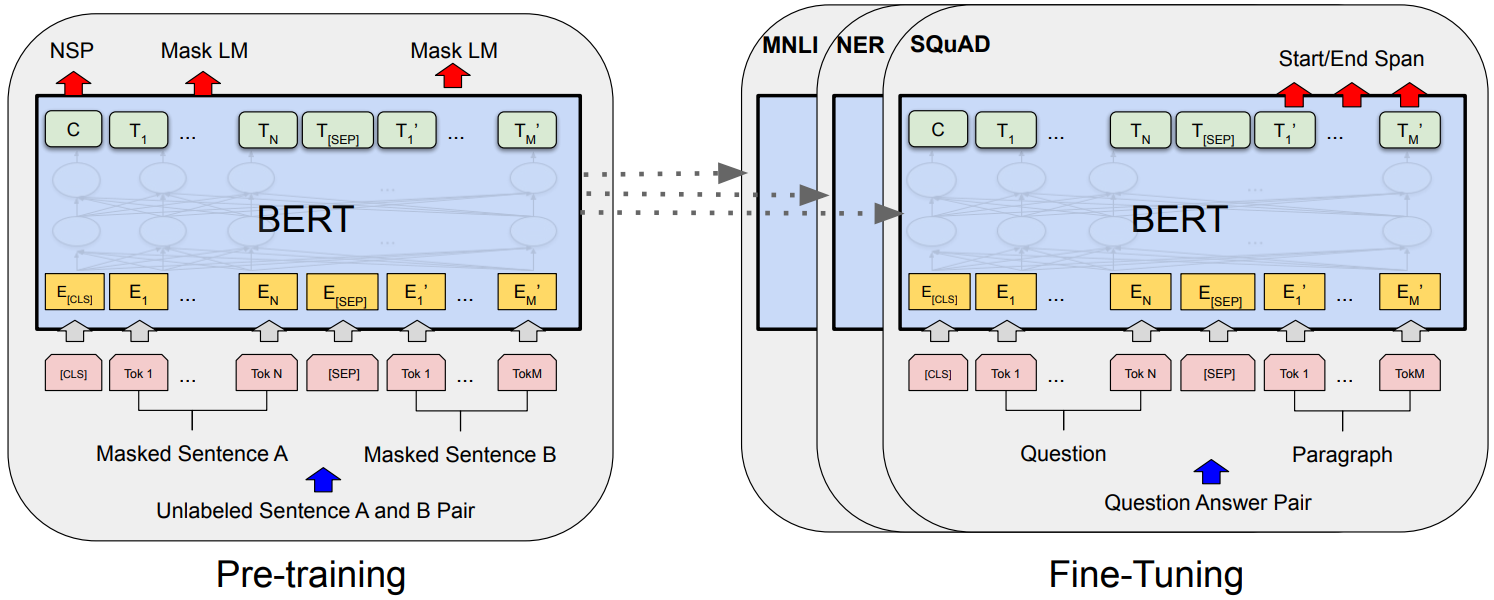
BERT fine-tuning for different tasks (Devlin et al., 2019)
Key Takeaways
- Original Transformer: Encoder-decoder with attention mechanisms
- Encoder-only (BERT): Bidirectional context, best for understanding
- Decoder-only (GPT): Causal context, best for generation
- [CLS] Token: Aggregates sequence representation for classification
- Text Embeddings: [CLS] output provides dense vector for downstream tasks
Next: We’ll see how these architectures power recommendation systems!